Scrapy 源码阅读(二):看源码
(接上文 Scrapy 源码阅读(一):Twisted 基础和 Scrapy 数据流
3 看源码
注意:本节内容基于 Scrapy 1.7
不知道大家有没有这样的体会?平时写业务代码的时候,一般是不会去关注各个模块怎么关联起来的。我要写控制器、写服务层、写模型层等,就按部就班的找到相应目录下的文件开始写了。当碰到问题在网上找不到好的解决方法或者闲时想学习一些设计方法的时候,我们就会去关注某些模块的底层实现以及它们的关系。这里我会用一个类似的方式,先给大家了解下 Scrapy 中的主要几个类的关系,在熟悉了这些类后,再根据需要去关注特定的类之间是如何关联的。
3.1 了解常见的几个类以及它们的关系
先理清楚几个类的关系
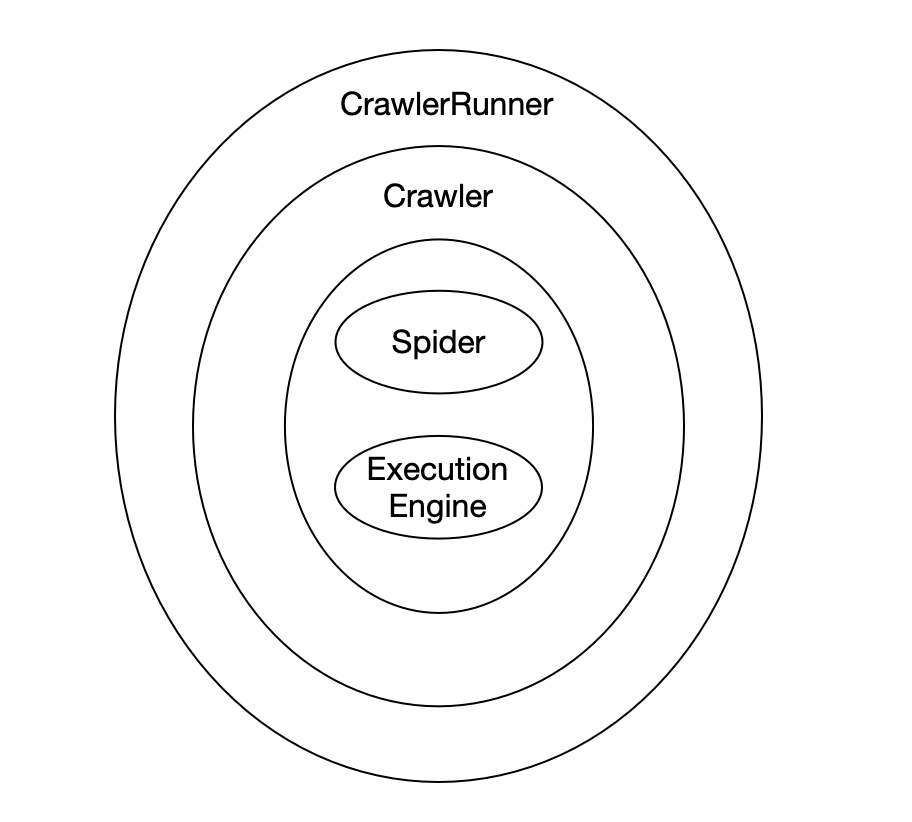
- Crawler 可以理解为爬虫的一个容器
- CrawlerRunner 对 Crawler 做了一些封装,可以让我们更方便的运行爬虫。类似的还有 CrawlerProcess,它是 CrawlerRunner 的子类
- Spider 就是我们编写爬虫文件时依赖的类,ExecutionEngine 则是 Scrapy 调度的核心
ExecutionEngine 的几个重要属性
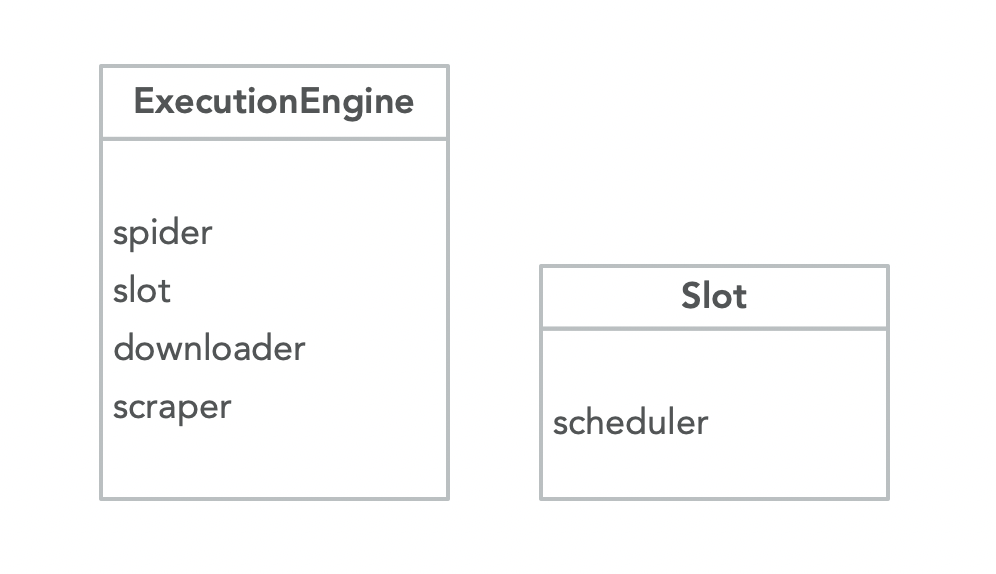
- spider,Crawler 中传递过来的 Spider 对象
- slot,插槽,用于请求存储以及调度
- scheduler,一般是 scrapy.core.scheduler. Scheduler 的对象
- downloader,一般是 crapy.core.downloader. Downloader 的对象
- scraper,一般是 scrapy.core.scraper. Scraper 的对象
上面的 spider、scheduler、downloader 的作用与之前数据流中对应部件的作用一致,scraper 与 Spider Middleware 和 Item Pipelines 有关。
另外,除了 ExecutionEngine 有 slot 属性外,downloader 和 scraper 都有对应的 slot,前者使用多个 slot 进行并发控制、延迟下载以及记录下载中的请求,后者用于记录响应和对应的请求。
3.2 从入口开始分析
简单的认识了主要的几个类之后,我们来跟下代码。运行爬虫时,很多时候我们会这么执行
$ scrapy crawl <spider_name>看下这个 scrapy 可执行文件
#!/Users/kevinbai/.pyenv/versions/3.7.5/envs/site_analysis/bin/python3.7
# -*- coding: utf-8 -*-
import re
import sys
from scrapy.cmdline import execute
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw?|\.exe)?$', '', sys.argv[0])
sys.exit(execute())PS:使用不同管理工具,可执行文件的路径有差别,上面的虚拟环境是由 pyenv 创建,你要根据自己的情况去找下。
原来就是调用 scrapy.cmdline.execute 方法
# scrapy/cmdline.py
def execute(argv=None, settings=None):
...
cmd.crawler_process = CrawlerProcess(settings)
_run_print_help(parser, _run_command, cmd, args, opts)
sys.exit(cmd.exitcode)这个方式是命令行的入口,根据项目配置做了一些基础的配置,并使用 CrawlerProcess 作为爬虫的执行环境。看下 crawl 命令
# scrapy/commands/crawl.py
class Command(ScrapyCommand):
...
def run(self, args, opts):
...
self.crawler_process.crawl(spname, **opts.spargs)
self.crawler_process.start()
if self.crawler_process.bootstrap_failed:
self.exitcode = 1这里调用了 CrawlerProcess 的 crawl 和 start 方法。先看下后者
# scrapy/crawler.py
class CrawlerProcess(CrawlerRunner):
...
def start(self, stop_after_crawl=True):
...
reactor.installResolver(self._get_dns_resolver())
tp = reactor.getThreadPool()
tp.adjustPoolsize(maxthreads=self.settings.getint('REACTOR_THREADPOOL_MAXSIZE'))
reactor.addSystemEventTrigger('before', 'shutdown', self.stop)
reactor.run(installSignalHandlers=False) # blocking call做了这么几件事
- 自定义 DNS 解析器
- 根据配置调整线程池,这个线程池将会用于解析 DNS,因为 Scrapy 解析 DNS 时,会用到 socket 库,只能使用多线程进行并发
- 绑定回调,当程序要结束时停止当前运行的爬虫
- 启动 reactor
至于爬虫是怎么创建的,引擎内部是怎么调度的,就要从 crawl 方法开始看了
# scrapy/crawler.py
class Crawler(object):
...
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
self.spider = self._create_spider(*args, **kwargs)
self.engine = self._create_engine()
start_requests = iter(self.spider.start_requests())
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
...- 首先是创建爬虫 spider
- 然后将 spider 和初始请求的迭代器作为参数创建引擎 engine
- 执行 engine 的
open_spider方法并启动 engine
PS:关于异常处理的代码,我都删除了,这有助于我们理解代码的核心思路
3.3 ExecutionEngine
看下 open_spider
# scrapy/core/engine.py
class ExecutionEngine(object):
# ...
@defer.inlineCallbacks
def open_spider(self, spider, start_requests=(), close_if_idle=True):
assert self.has_capacity(), "No free spider slot when opening %r" % \
spider.name
logger.info("Spider opened", extra={'spider': spider})
nextcall = CallLaterOnce(self._next_request, spider)
scheduler = self.scheduler_cls.from_crawler(self.crawler)
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot = slot
self.spider = spider
yield scheduler.open(spider)
yield self.scraper.open_spider(spider)
self.crawler.stats.open_spider(spider)
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
slot.nextcall.schedule()
slot.heartbeat.start(5)- 首先检查 engine 的 slot 是否空闲,这里 1 个 engine 只能运行 1 个 spider
- 然后是一些属性的初始化以及启动,我们可以分成 3 部分来看:一是 slot 里面的属性,二是 crawler 的属性,最后就是 engine 的直接属性
先了解下上面出现的 CallLaterOnce 的用法
# scrapy/utils/reactor.py
class CallLaterOnce(object):
def __init__(self, func, *a, **kw):
self._func = func
self._a = a
self._kw = kw
self._call = None
def schedule(self, delay=0):
if self._call is None:
self._call = reactor.callLater(delay, self)
def cancel(self):
if self._call:
self._call.cancel()
def __call__(self):
self._call = None
return self._func(*self._a, **self._kw)这个类的目的其实就是实现 callLater 的功能,不同的是我们可以 schedule 多次,在一定时间内只会调度 1 个任务到事件循环里面去,如果直接使用 callLater 的话,会重复添加很多个任务到事件循环里面去,影响执行效率。看个例子
def f(arg):
# 请求等 IO 操作
nextcall = CallLaterOnce(f, 'some arg')
nextcall.schedule(5)
nextcall.schedule(5)
nextcall.schedule(5)这里 nextcall 虽说被 schedule 了多次,但是只有第 1 次的 schedule 是有效的,最终只添加了 1 个任务到事件循环。Scrapy 很多地方都会调用 _next_request ,内部又都是并发操作,难免会碰到短时间内同时调用这个方法,这里便使用了 CallLaterOnce 降低处理压力。
看下 Slot 的构造函数
# scrapy/core/engine.py
class Slot(object):
def __init__(self, start_requests, close_if_idle, nextcall, scheduler):
self.closing = False
self.inprogress = set() # requests in progress
self.start_requests = iter(start_requests)
self.close_if_idle = close_if_idle
self.nextcall = nextcall
self.scheduler = scheduler
self.heartbeat = task.LoopingCall(nextcall.schedule)- inprogress,记录当前正在处理的请求
- start_requests,爬虫的初始化请求
- nextcall,封装了
_next_request方法的 CallLaterOnce - scheduler,调度器,里面存放待爬取的请求
- heartbeat,心跳,每隔一段时间执行一次
_next_request
简单看下 Scheduler 的构造方法
# scrapy/core/scheduler.py
class Scheduler(object):
def __init__(self, dupefilter, jobdir=None, dqclass=None, mqclass=None,
logunser=False, stats=None, pqclass=None, crawler=None):
self.df = dupefilter
self.dqdir = self._dqdir(jobdir)
self.pqclass = pqclass
self.dqclass = dqclass
self.mqclass = mqclass
self.logunser = logunser
self.stats = stats
self.crawler = crawler- df,去重器
- dqdir,启动爬虫时,我们指定的持久化目录 jobdir
- pqclass,优先级队列类型
- dqclass、mqclass 分别是磁盘和内存队列类型。当我们指定了 jobdir 后,主要是用磁盘队列
- stats,主要用于统计内存状态,在 Crawler 的构造函数中开始被创建,然后一级一级的传到这来的
上面的类具体是是指那些类,可以看 Scheduler 的 from_crawler 方法。关于怎么入队列、出队列等比较详细的操作,这里不展开,感兴趣的可以看下这个类。
回到 engine 的 open_spider 方法,这个时候 slot 相关的初始化以及启动,我们应该大致能理解了。后面依次启动了 scraper 和 crawler.stats,需要注意的是 downloader 是在 engine 刚创建的时候就已经初始化好了。另外,当这些都初始化好后,engine 发出了 spider_opened 信号。
前面我们提到过 _next_request 多次,我们顺着这个方法跟下去。
# scrapy/core/engine.py
class ExecutionEngine(object):
# ...
def _next_request(self, spider):
# ...
while not self._needs_backout(spider):
if not self._next_request_from_scheduler(spider):
break
if slot.start_requests and not self._needs_backout(spider):
try:
request = next(slot.start_requests)
except StopIteration:
# ...
else:
self.crawl(request, spider)
if self.spider_is_idle(spider) and slot.close_if_idle:
self._spider_idle(spider)这个方法主要是做 2 个事情
- 从 scheduelr 中获取请求并下载,涉及方法
_next_request_from_scheduler - 从 spider 初始请求中获取请求加入 scheduler,涉及方法 crawl
先看后者 crawl
class ExecutionEngine(object):
# ...
def crawl(self, request, spider):
assert spider in self.open_spiders, \
"Spider %r not opened when crawling: %s" % (spider.name, request)
self.schedule(request, spider)
self.slot.nextcall.schedule()
def schedule(self, request, spider):
self.signals.send_catch_log(signal=signals.request_scheduled,
request=request, spider=spider)
if not self.slot.scheduler.enqueue_request(request):
self.signals.send_catch_log(signal=signals.request_dropped,
request=request, spider=spider)就是调用了 schedule 然后触发下一次 _next_request。schedule 中发出 request_scheduled 信号后,将请求加入 scheduler 的队列,之后又发出 request_dropped 信号。
再看前者 _next_request_from_scheduler
class ExecutionEngine(object):
# ...
def _next_request_from_scheduler(self, spider):
slot = self.slot
request = slot.scheduler.next_request()
if not request:
return
d = self._download(request, spider)
d.addBoth(self._handle_downloader_output, request, spider)
d.addErrback(lambda f: logger.info('Error while handling downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.remove_request(request))
d.addErrback(lambda f: logger.info('Error while removing request from slot',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.nextcall.schedule())
d.addErrback(lambda f: logger.info('Error while scheduling new request',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))主要做了这么几件事
- 从 scheduler 中获取下一个请求,没有则退出
- 下载请求,将请求加入 slot 的 inprogress 集合中,涉及方法
_download - 下载完成后,将响应放到 scraper 中,涉及方法
_handle_downloader_output - 下载完成后,将请求从 slot 的 inprogress 集合中移除
- 下载完成,触发下一次
_next_request
看下 _download
class ExecutionEngine(object):
# ...
def _download(self, request, spider):
slot = self.slot
slot.add_request(request)
def _on_success(response):
assert isinstance(response, (Response, Request))
if isinstance(response, Response):
response.request = request # tie request to response received
logkws = self.logformatter.crawled(request, response, spider)
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
self.signals.send_catch_log(signal=signals.response_received, \
response=response, request=request, spider=spider)
return response
def _on_complete(_):
slot.nextcall.schedule()
return _
dwld = self.downloader.fetch(request, spider)
dwld.addCallbacks(_on_success)
dwld.addBoth(_on_complete)
return dwld- 将请求加入 slot 的 inprogress 集合
- 调用 downloader 的 fetch 方法,具体做了些什么后面会分析
- 下载成功后,打印成功日志,并发送
response_received信号 - 下载成功或者失败后,都会触发下一次
_next_request
3.4 Downloader
看下 fetch 方法
# scrapy/core/downloader/__init__.py
class Downloader(object):
# ...
def fetch(self, request, spider):
def _deactivate(response):
self.active.remove(request)
return response
self.active.add(request)
dfd = self.middleware.download(self._enqueue_request, request, spider)
return dfd.addBoth(_deactivate)- 首先还是将请求加入 downloader 的活跃集合 active
- 然后调用自己的 DownloaderMiddlewareManager 实例的 download 方法触发
_enqueue_request下载请求 - 下载完成后,将请求从 active 中移除
在看方法 _enqueue_request 之前,我们先看下 download 的定义
# scrapy/core/downloader/middleware.py
class DownloaderMiddlewareManager(MiddlewareManager):
# ...
def download(self, download_func, request, spider):
@defer.inlineCallbacks
def process_request(request):
for method in self.methods['process_request']:
response = yield method(request=request, spider=spider)
if response is not None and not isinstance(response, (Response, Request)):
raise _InvalidOutput('Middleware %s.process_request must return None, Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, response.__class__.__name__))
if response:
defer.returnValue(response)
defer.returnValue((yield download_func(request=request, spider=spider)))
@defer.inlineCallbacks
def process_response(response):
# ...
@defer.inlineCallbacks
def process_exception(_failure):
# ...
deferred = mustbe_deferred(process_request, request)
deferred.addErrback(process_exception)
deferred.addCallback(process_response)
return deferred- 首先触发
process_request,调用所有已注册的下载中间件中的process_request方法,然后调用_enqueue_request - 下载成功后,执行
process_exception - 下载失败后,执行
process_response
如果之前写过下载器中间件,你会发现你这里的 3 个以 process_ 开头的方法和中间件一一对应。的确,这里就是调度下载器中间件的底层实现。
回到 _enqueue_request
# scrapy/core/downloader/__init__.py
class Downloader(object):
# ...
def _enqueue_request(self, request, spider):
key, slot = self._get_slot(request, spider)
request.meta[self.DOWNLOAD_SLOT] = key
def _deactivate(response):
slot.active.remove(request)
return response
slot.active.add(request)
self.signals.send_catch_log(signal=signals.request_reached_downloader,
request=request,
spider=spider)
deferred = defer.Deferred().addBoth(_deactivate)
slot.queue.append((request, deferred))
self._process_queue(spider, slot)
return deferred和 engine 类似,downloader 里面也有 slot 的概念,不过 1 个 downloader 有多个 slot。不同的 slot 主要是用于控制不同的并发、延迟下载,同时也会记录下载中的请求。
做了这么几件事
- 根据请求获取 slot,并将当前请求加入到对应 slot 的活跃集合 active 中
- 发送
request_reached_downloader信号 - 将请求加入下载队列,调用
_process_queue会触发下载方法,下载完成后又触发_deactivate将当前请求从 slot 的 active 中移除
具体 _process_queue 又做了什么呢
class Downloader(object):
# ...
def _process_queue(self, spider, slot):
if slot.latercall and slot.latercall.active():
return
# Delay queue processing if a download_delay is configured
now = time()
delay = slot.download_delay()
if delay:
penalty = delay - now + slot.lastseen
if penalty > 0:
slot.latercall = reactor.callLater(penalty, self._process_queue, spider, slot)
return
# Process enqueued requests if there are free slots to transfer for this slot
while slot.queue and slot.free_transfer_slots() > 0:
slot.lastseen = now
request, deferred = slot.queue.popleft()
dfd = self._download(slot, request, spider)
dfd.chainDeferred(deferred)
# prevent burst if inter-request delays were configured
if delay:
self._process_queue(spider, slot)
break- 如果当前的 slot 已经有计划下次执行了,直接退出
- 如果当前的 slot 需要延迟下载,并且还没到执行时间,则使用 callLater 其加入事件循环延迟下载,并将返回结果赋值给 slot 的 latercall
- 如果当前的 slot 的下载队列有未处理的请求并且没达到并发限制,执行下载方法
_download
class Downloader(object):
# ...
def _download(self, slot, request, spider):
dfd = mustbe_deferred(self.handlers.download_request, request, spider)
def _downloaded(response):
self.signals.send_catch_log(signal=signals.response_downloaded,
response=response,
request=request,
spider=spider)
return response
dfd.addCallback(_downloaded)
slot.transferring.add(request)
def finish_transferring(_):
slot.transferring.remove(request)
self._process_queue(spider, slot)
return _
return dfd.addBoth(finish_transferring)- 针对不同的协议调用不同的 hanler 下载请求,比如有 HTTP、FTP 等 handler,感兴趣的可以从
download_request跟下去,这里不展开 - 注册成功回调,下载完成后,发送
response_downloaded信号 - 将请求加入 slot 的正在传输的集合 transferring
- 注册成功和失败回调,完成后从 slot 的 transferring 移除当前请求,并再次触发
_process_queue方法
3.5 ExecutionEngine 和 Scraper 关联的地方
跟了这么远,我们现在回到 ExecutionEngine 中的 _next_request_from_scheduler 方法,为了方便,我把这段代码再复制下放到这里来
# scrapy/core/engine.py
class ExecutionEngine(object):
# ...
def _next_request_from_scheduler(self, spider):
slot = self.slot
request = slot.scheduler.next_request()
if not request:
return
d = self._download(request, spider)
d.addBoth(self._handle_downloader_output, request, spider)
d.addErrback(lambda f: logger.info('Error while handling downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.remove_request(request))
d.addErrback(lambda f: logger.info('Error while removing request from slot',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.nextcall.schedule())
d.addErrback(lambda f: logger.info('Error while scheduling new request',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))再跟下 _handle_downloader_output
class ExecutionEngine(object):
# ...
def _handle_downloader_output(self, response, request, spider):
assert isinstance(response, (Request, Response, Failure)), response
# downloader middleware can return requests (for example, redirects)
if isinstance(response, Request):
self.crawl(response, spider)
return
# response is a Response or Failure
d = self.scraper.enqueue_scrape(response, request, spider)
d.addErrback(lambda f: logger.error('Error while enqueuing downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))- 如果 response 是请求的话,执行 crawl。因为响应会经过下载器中间件,所以有可能返回的是请求
- 将响应以及请求加到 scraper 的处理队列中,这部分操作和 Spider Middleware 和 Item Pipelines 有关联。感兴趣的也可以像跟 downloader 那样慢慢跟下去,多看几遍,应该能大致理解,这里也不展开了
3.6 一点体会
看完上面的分析过程,如果你的思路跟着走了一遍,应该对类及其之前的关系有一定程度的理解了,并能够和数据流中的各个部件对应起来。看源码的时候,相信大家都有类似的感觉,就是看着看着不知道自己在哪了,所以看代码的时候一定要集中注意力,将自己当前所看的地方和数据流结合起来,记住常看的类的几个关键属性以及方法(比如 engine 的 nextcall 属性、 crawl、_next_request、_next_request_from_scheduler 方法等等),这样既能让你加深理解,也能让你能够更快的在代码不同的地方进行跳转,不迷路,提高学习效率。
4 小结
本文先是介绍了阅读源码必须的 Twisted 知识,然后梳理了下 Scrapy 现有的功能,最后通过图和源码的方式,从入口文件(函数)开始一步一步的跟下去,大致的分析了数据流图中的几个主要部件对应的类以及它们之间的关系。分析过程并没有囊括框架的方方面面,但是如果你理解了文中的分析过程,当你碰到框架内部的问题,相信能更快的定位位置,并理解相应的源码。