Scrapy 源码阅读(一):Twisted 基础和 Scrapy 数据流
本文记录下自己看 Scrapy 源码的一点经验,没有涉及框架的方方面面,更多的是关注数据的流转以及代码的组织。如果你想深入框架的某个细节,那么这篇文字可以给你一个切入点。
阅读源码常规的步骤
- 准备好必须的基础知识
- 熟悉框架有哪些功能
- 看源码,了解代码是怎么组织的,最后按需关注特定部分的实现细节
我们一步一步来。
1 Twisted
Scrapy 基于 Twisted,所以除了要有一定的 Python 基础外,还要对 Twisted 有一些了解。
你可以将 Twisted 和 Asyncio 类比,它们都是为了支持协程而诞生的,只是前者比后者出现的更早。这 2 个技术实现的核心都是事件循环,当程序执行到某个耗时的 IO 操作时,程序的执行权限会被退回给事件循环,事件循环会检测其它准备就绪的协程,然后将执行权限交给它,当之前的协程 IO 操作完毕后,事件循环会将执行权限转给它,继续后面的操作。这样,就能在单线程内实现并发,作用和多线程类似,只是比多线程更轻量。事件循环在 Asyncio 中被叫做 event_loop,在 Twisted 中叫做 reactor。我们看一些简单的例子
1.1 Schedule
- 多少秒后执行某个任务
from twisted.internet import reactor
def f(s):
print('this will run 3.5 seconds after it was scheduled: %s' % s)
reactor.callLater(3.5, f, 'hello, world')
# f() will only be called if the event loop is started.
reactor.run()reactor.callLater 会将某个任务加入到事件循环,并设置好多少秒后开始执行,当然要将事件循环启动后才会有作用。
- 每隔多少秒执行某个任务
from twisted.internet import reactor, task
def f(s):
print(s)
loop = task.LoopingCall(f, 'hello, world')
# Start looping every 1 second.
loop.start(1)
reactor.run()每隔 1s 执行一次 f 方法。
1.2 Deferred
Deferred 表示某个任务未来会产生结果,当任务执行完毕后,会执行注册在 Deferred 的回调函数,并将结果传递给它。
1.2.1 成功回调
from twisted.internet import reactor, defer
def get_dummpy_data(input_data):
print('get_dummpy_data called')
deferred = defer.Deferred()
reactor.callLater(2, deferred.callback, input_data * 3)
return deferred
def cb_print_data(result):
print('Result received: {}'.format(result))
deferred = get_dummpy_data(3)
deferred.addCallback(cb_print_data)
# manually set up the end of the process by asking the reactor to
# stop itself in 4 seconds time
reactor.callLater(4, reactor.stop)
reactor.run()get_dummpy_data,返回了 1 个 defer. Deferred 对象,表示该函数是 1 个异步任务,会在未来某个时间点产生结果,这里使用
reactor.callLater(2, deferred.callback, input_data * 3)模仿异步结果,2s 后执行 deferred 的回调函数,并将计算后的结果传递给它。
cb_print_data,简单的打印结果。
看下执行流程,首先调用 get_dummpy_data 得到 deferred,然后注册回调函数 cb_print_data,最后运行事件循环。为了让程序正常关闭,还设置了在 4s 后自动关闭事件循环。执行结果
get_dummpy_data called
Result received: 91.2.2 异常回调
上面我们使用 addCallback 注册成功回调,除开这个,我们还能注册异常回调,实现异常处理。
from twisted.internet import reactor, defer
def get_dummpy_data(input_data):
print('get_dummpy_data called')
deferred = defer.Deferred()
if input_data % 2 == 0:
reactor.callLater(2, deferred.callback, input_data * 3)
else:
reactor.callLater(2, deferred.errback, ValueError('You used an odd number!'))
return deferred
def cb_print_data(result):
print('Result received: {}'.format(result))
def eb_print_error(failure):
print(failure)
deferred = get_dummpy_data(3)
deferred.addCallback(cb_print_data)
deferred.addErrback(eb_print_error)
reactor.callLater(4, reactor.stop)
reactor.run()get_dummpy_data,当 input_data 为奇数时,2s 后会触发 deferred 的异常回调。
执行时,使用 addErrback 注册异常回调。结果
get_dummpy_data called
[Failure instance: Traceback (failure with no frames): <class 'ValueError'>: You used an odd number!
]1.2.3 回调链
看到这里,有的读者可能会想如果我注册多个成功回调以及多个异常回调,成功或者异常时,具体的执行流程又是怎么样的呢?这就要引入回调链的概念了。看下图
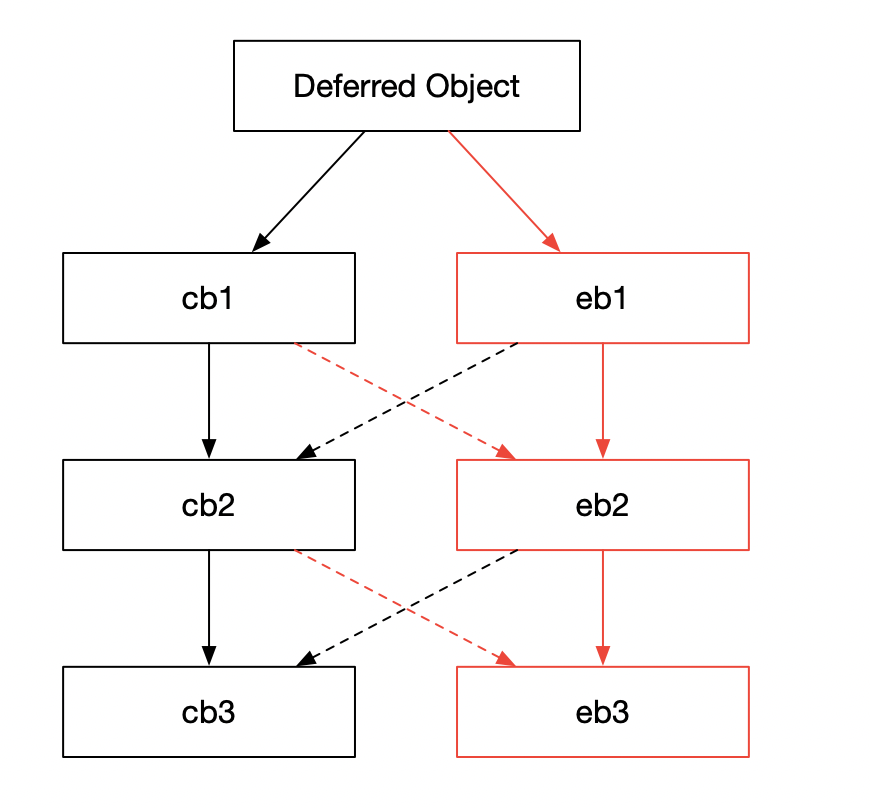
有 2 种类型的主链:成功以及异常回调链
- 对于前者来说,每个回调的结果都是下个回调的输入,比如 cb1 的结果会是 cb2 的输入
- 对于后者来说,某个回调返回异常或者抛出异常,就会将异常作为下一个回调的输入,比如 eb1 如果返回或者抛出异常,那么 eb2 会被调用,并将 eb1 返回或者抛出的异常作为参数
当然,还有其它情况
- 如果 cb1 异常,那么 eb2 会被调用,并将 cb1 中的异常作为参数
- 如果 eb1 处理了异常并返回值,那么 cb2 会被调用,并将 eb1 的返回值作为参数
也就是说,当前级别的回调只根据上一级别的回调的执行情况进行触发。
添加回调大概有下面几种方式
- addCallback、addErrback
- addCallbacks
- addBoth
这些方式有些细节上的不同,举例说明下
第 1 个例子
d = getDeferredFromSomewhere()
d.addCallback(cb1) # A
d.addErrback(eb1) # B
d.addCallback(cb2)
d.addErrback(eb2)对应图
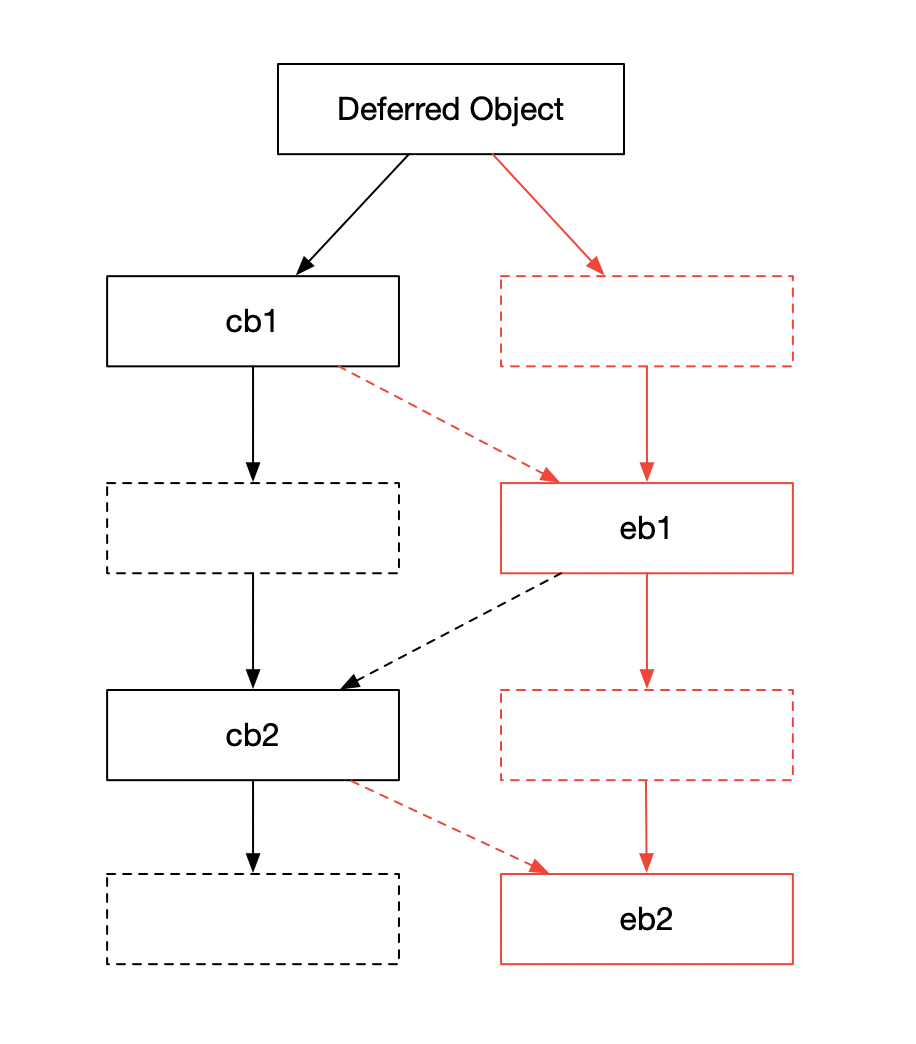
也即,对于每 1 次 addCallback(addErrback),都会在同一级上绑定 1 个成功回调(异常回调)和 1 个什么都不做的异常回调(成功回调)。
第 2 个例子
d = getDeferredFromSomewhere()
d.addCallbacks(cb1, eb1) # C
d.addCallbacks(cb2, eb2)对应图
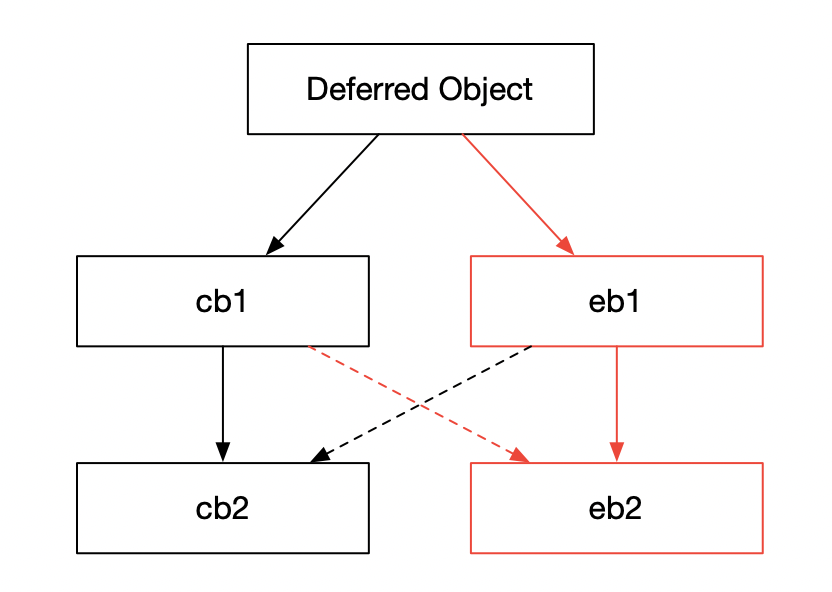
也即,addCallbacks 会在同一级别上绑定 1 个成功回调和 1 个异常回调。
为了加强我们的理解,可以想下这个问题,如果 cb1 出现异常,对于这 2 个例子的执行情况有什么差别?结合图其实很好理解,对于第 1 个例子,eb1 会被调用;对于第 2 个例子,eb2 会被调用。
至于 addBoth(cb),可以理解为
d = getDeferredFromSomewhere()
d.addCallback(cb)
d.addErrback(cb)1.2.4 DeferredList
当碰到需要等待多个 deferred 执行完毕的时候,我们可以使用 DeferredList
dl = defer.DeferredList([deferred1, deferred2, deferred3])看个例子
from twisted.internet import defer
def print_result(result):
for (success, value) in result:
if success:
print('Success:', value)
else:
print('Failure:', value.getErrorMessage())
deferred1 = defer.Deferred()
deferred2 = defer.Deferred()
deferred3 = defer.Deferred()
dl = defer.DeferredList([deferred1, deferred2, deferred3], consumeErrors=True)
dl.addCallback(print_result)
deferred1.callback('one')
deferred2.errback(Exception('bang!'))
deferred3.callback('three')- 创建 3 个 deferred,使用 DeferredList 等待这 3 个 deferred,同时得到新的 deferred dl,consumeErrors 会屏蔽这 3 个 deferred 中的异常(如果有的话)
- 添加成功回调
print_result,需要注意的是,DeferredList 是不会触发异常回调的,即使你没有设置 consumeErrors 并注册了异常回调 - 给 deferred1 和 deferred3 设置返回值,给 deferred2 设置异常
- DeferredList 的结果是由元祖构成的列表,每个元祖代表一个之前传入的 deferred 的结果。元祖有 2 个值,第 1 个是布尔值,True 表示 deferred 没有异常,False 表示有,第 2 个是真正的结果。元祖的顺序和传入的 deferred 一一对应。清楚了这些,
print_result也就好理解了
看下执行结果
Success: one
Failure: bang!
Success: three1.2.5 gatherResults
gatherResults 和 DeferredList 类似,也是等待多个 deferred,不同的是
- 只要有 1 个 deferred 异常,就会触发整体的异常
- 返回的结果列表中的元素不是一个元祖,而是对应 deferred 的真正的结果。因为只要有 1 个 deferred 发生异常就会触发整体的异常回调,所以成功回调表示所有的 deferred 都是执行成功了的,也就没有必要使用布尔值表示是否成功执行了。
from twisted.internet import defer
d1 = defer.Deferred()
d2 = defer.Deferred()
d = defer.gatherResults([d1, d2])
def print_result(result):
print(result)
d.addBoth(print_result)
d1.callback('one')
d2.errback(Exception('bang!'))- 创建了 2 个 deferred d1 和 d2,使用 gatherResults 等待它们得到 d
- 注册 d 的成功和异常回调都为
print_result - d1 设置返回值,d2 设置异常
看下执行结果
[Failure instance: Traceback (failure with no frames): <class 'twisted.internet.defer.FirstError'>: FirstError[#1, [Failure instance: Traceback (failure with no frames): <class 'Exception'>: bang!
]]
]
Unhandled error in Deferred:
Traceback (most recent call last):
Failure: builtins.Exception: bang!如果 gatherResults 时,设置了 consumeErrors 为 True,不会有 Unhandled error in Deferred: 及其之后的输出。
如果将
d2.errback(Exception('bang!'))改为
d2.callback('two')结果为
['one', 'two']1.3 defer.inlineCallbacks
在 Scrapy 源码中,我们经常会看到类似这样的语法
@defer.inlineCallbacks
def f():
...这可以理解为一个语法糖,表示在被这个装饰器装饰过的方法里面,可以使用 yield 等待 deferred 的结果,我们可以改写 1.2.1 中的例子为
from twisted.internet import reactor, defer
def get_dummpy_data(input_data):
print('get_dummpy_data called')
deferred = defer.Deferred()
reactor.callLater(2, deferred.callback, input_data * 3)
return deferred
@defer.inlineCallbacks
def main():
result = yield get_dummpy_data(3)
print(result)
main()
reactor.callLater(4, reactor.stop)
reactor.run()1.4 更多
如果只是想简单的看懂 Scrapy 源码的话,关于 Twisted,理解上面的一些概念就差不多了。虽说源码里面还是一些上面没提及的方法,比如 maybeDeferred 等,不过有上面的一些基础后,你通过查看官方文档或者跳转方法定义处读读,也能较快的理解其用处了。
如果想比较全面的掌握 Twisted,可以先看一本书《Twisted. Network. Programming》,这本书可以帮你更为全面的理解 Twisted 的一些基本概念。读完此书后,再根据需要去读官方文档的特定部分,就要轻松一些了。
2 框架有哪些功能
要知道一个框架有些什么功能,可以看它的官方文档。刚接触 Scrapy 的同学一看文档,可能会觉得功能有点多,有点杂。其实,我们可以看下它的数据流图,就可以将其主要的功能给串起来了。
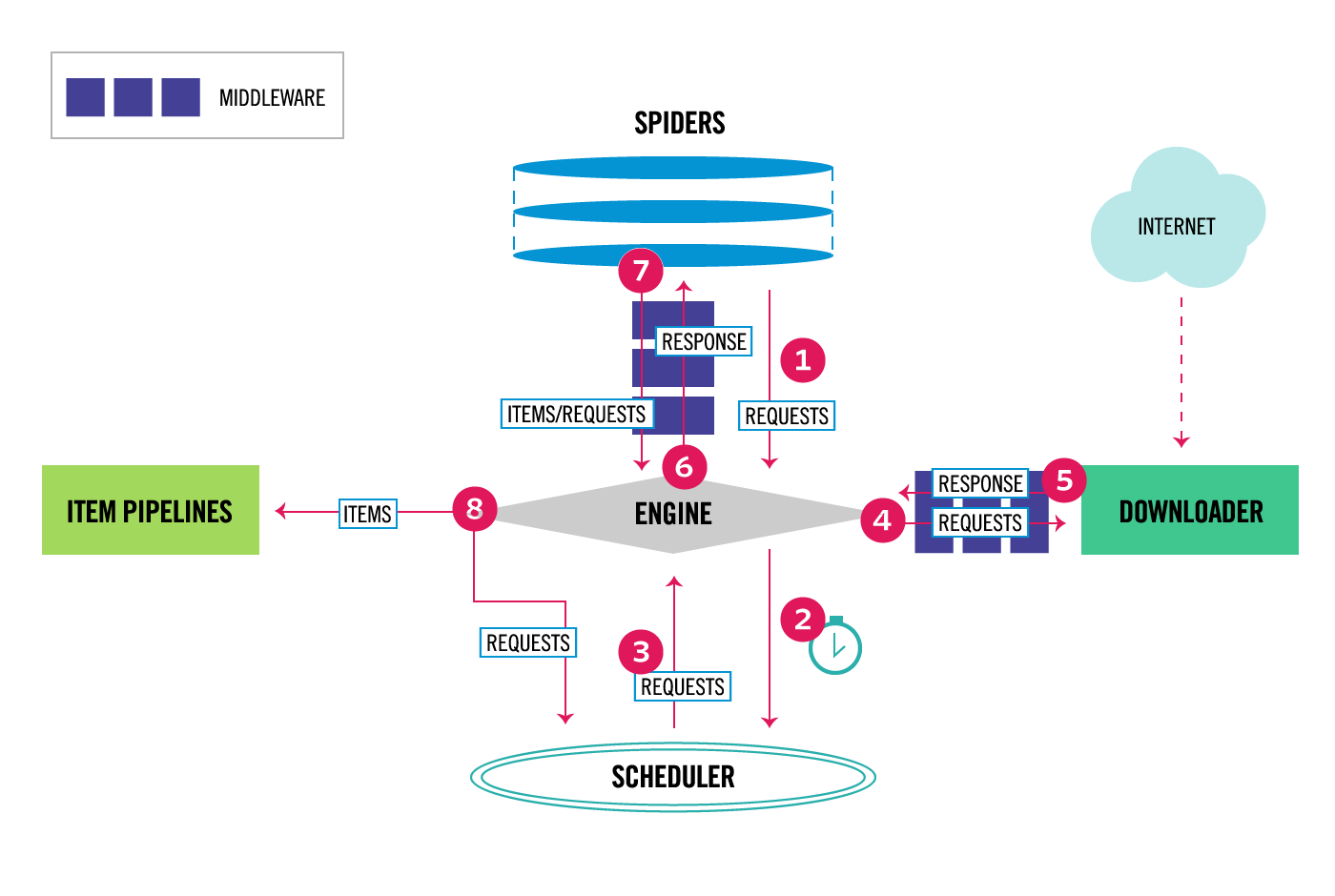
从图上可以直观的看出,Scrapy 的主要部件有 Engine、Spider、Scheduler、Downloader、Item Pipelines 以及中间件。
更详细的功能,我们就可以通过主要部件去联想。比如:
- Spider 涉及 Request、Response、Selector、Extractor
- Scheduler 涉及去重的 DupeFilter
- Downloader 涉及并发量、下载延时等设置
- Item Pipelines 涉及 Items、Item Loaders、Feed Exports
- 至于中间件,在 Spider 和 Engine 中间的是 Spider Middleware,在 Engine 和 Downloader 中间的是 Downloader Middleware
除此之外,文档上还列了一些内置服务以及解决特定问题的示例,比如:Stats Collection 可以用于统计;Telnet Console 可以查看运行时爬虫的状态、内存使用情况等;对于广度优先的爬虫怎么设置;等等。
上面的联想只是作为一个参考,不同的人有不同的联想方式。
这样一来,我们就了解了框架的大部分功能了。不过,我还是推荐在使用 Scrapy 一段时间后,碰到特定的问题后,再去看相应的源码。一方面,那个时候,你会对框架的很多概念有更深的理解,看源码的时候更容易理解作者的用心;另一方面,如果只是范范的看源码,很难抓重点,很可能你看了一段时间后,感觉好像没有从中学到什么。
现在我们还是参考上面的图,来仔细看下框架中的数据流
- Spider 就是我们常写的那个 spider 文件,Engine 从
start_urls或者start_requests中获取初始请求 - Engine 将请求加入 Scheduler 并从中获取下一个请求
- Scheduler 返回给 Engine 下一个请求
- Engine 将请求发送给 Downloader,这会调用 Downloader Middleware 中的
process_request - 当 Downloader 下载完毕后会生成一个响应发送给 Engine,这会调用 Downloader Middleware 的
process_response - Engine 收到 Downloader 生成的响应后会将其发送给 Spider,这会调用 Spider Middleware 的
process_spider_input - 当 Spider 处理完响应后,会将生成的 Items 或者新的请求发送给 Engine,这会调用 Spider Middleware 的
process_spider_output - 如果 Spider 发送给 Engine 的有 Items,Engine 会将 Item 发送给 Item Pipelines;如果有新的请求,会将其加入 Scheduler;如果 Scheduler 还有未处理的请求的话,Engine 会向其获取下一个请求
- 重复步骤 1 直到 Scheduler 中的请求被处理完
到这里,看源码前的准备工作就差不多了。下一篇开始跟源码,感兴趣的伙伴可以关注下后面的文章。